OpenAI Structured Outputs 체크리스트: JSON mode 대신 schema strict로 응답 깨짐 줄이는 법

AI API 응답을 DB에 저장하거나 다음 처리 단계로 넘긴다면, 먼저 출력 형식을 계약처럼 고정해야 합니다. 기준일: 2026-06-25. OpenAI Structured Outputs는 그 계약을 JSON Schema로 적고, 응답이 깨졌을 때 처리할 예외까지 함께 설계할 때 쓸모가 큽니다.
핵심은 새 OpenAI API 작업을 Responses API 기준으로 설계하고, 출력은 json_schema와 strict: true로 묶은 뒤 서버에서 한 번 더 검증하는 흐름입니다. 값의 사실성은 출처 확인, 업무 규칙 검증, 사람 검토 단계로 따로 묶으면 운영 중 문제를 찾기 쉽습니다.
언제 Structured Outputs를 먼저 봐야 하나요?
자유로운 답변이 필요한 챗봇보다, 정해진 필드를 받아 다음 코드가 바로 처리해야 하는 작업에 맞습니다. 아래 표는 도입 여부를 빠르게 가르는 기준입니다.
| 상황 | 추천 방식 | 판단 기준 |
|---|---|---|
| 문의 내용을 카테고리, 긴급도, 담당자로 분류 | Structured Outputs | 필드가 고정되고 누락되면 후속 처리가 깨짐 |
| 외부 API를 호출해야 함 | Function calling | 모델이 도구 인자를 만들고 앱이 실행 결과를 돌려줘야 함 |
| 최신 웹 정보와 출처가 필요함 | Responses API의 web search 도구 검토 | 응답 안에 출처와 현재 기준 확인이 필요함 |
| 사람에게 자연어 설명만 보여줌 | 일반 텍스트 응답 | JSON 파싱 실패가 곧 서비스 장애로 이어지지 않음 |
JSON mode와 schema strict는 어떻게 다르게 봐야 하나요?
JSON mode는 “JSON처럼 답해줘”에 가깝고, schema strict는 “이 필드와 타입으로만 답해줘”에 가깝습니다. 제품 코드에서는 후자가 더 다루기 쉽지만, 스키마가 복잡할수록 실패 처리와 테스트 케이스가 더 중요해집니다.
- 필드 이름을 업무 언어로 정합니다.
category,priority,assignee_hint처럼 후속 코드가 바로 읽을 이름이 좋습니다. - 필수값을 명확히 둡니다. 빈 값이 허용되는 필드는
null가능 여부를 스키마에서 따로 정합니다. - 추가 필드는 기본적으로 막습니다. 모델이 친절하게 덧붙인 설명이 파서에서는 장애가 됩니다.
- 스키마 버전을 남깁니다. 운영 중 필드가 바뀌면 예전 로그와 새 응답을 구분해야 합니다.
운영 전 최소 체크리스트
처음부터 큰 스키마를 만들기보다, 실패했을 때 어느 단계에서 멈출지 정하는 편이 더 안전합니다. 작은 팀이라면 아래 순서만 지켜도 디버깅 시간이 꽤 줄어듭니다.
- 새 작업이면 Responses API 기준으로 입력, 출력, 도구 호출 구조를 잡습니다.
- 응답으로 꼭 필요한 필드만 JSON Schema에 넣고, 설명용 자연어는 별도 필드로 분리합니다.
strict: true를 쓰되, refusal, incomplete, max token 같은 예외 경로를 코드에 둡니다.- Zod, Pydantic, JSON Schema validator 중 프로젝트에 맞는 검증기를 한 번 더 붙입니다.
- 정상 예시보다 실패 예시를 먼저 테스트합니다. 빈 입력, 긴 입력, 모호한 입력, 정책상 거절될 입력을 넣어보면 됩니다.
- 로그에는 원문 전체보다 schema version, request id, validation error만 남기는 쪽이 안전합니다.
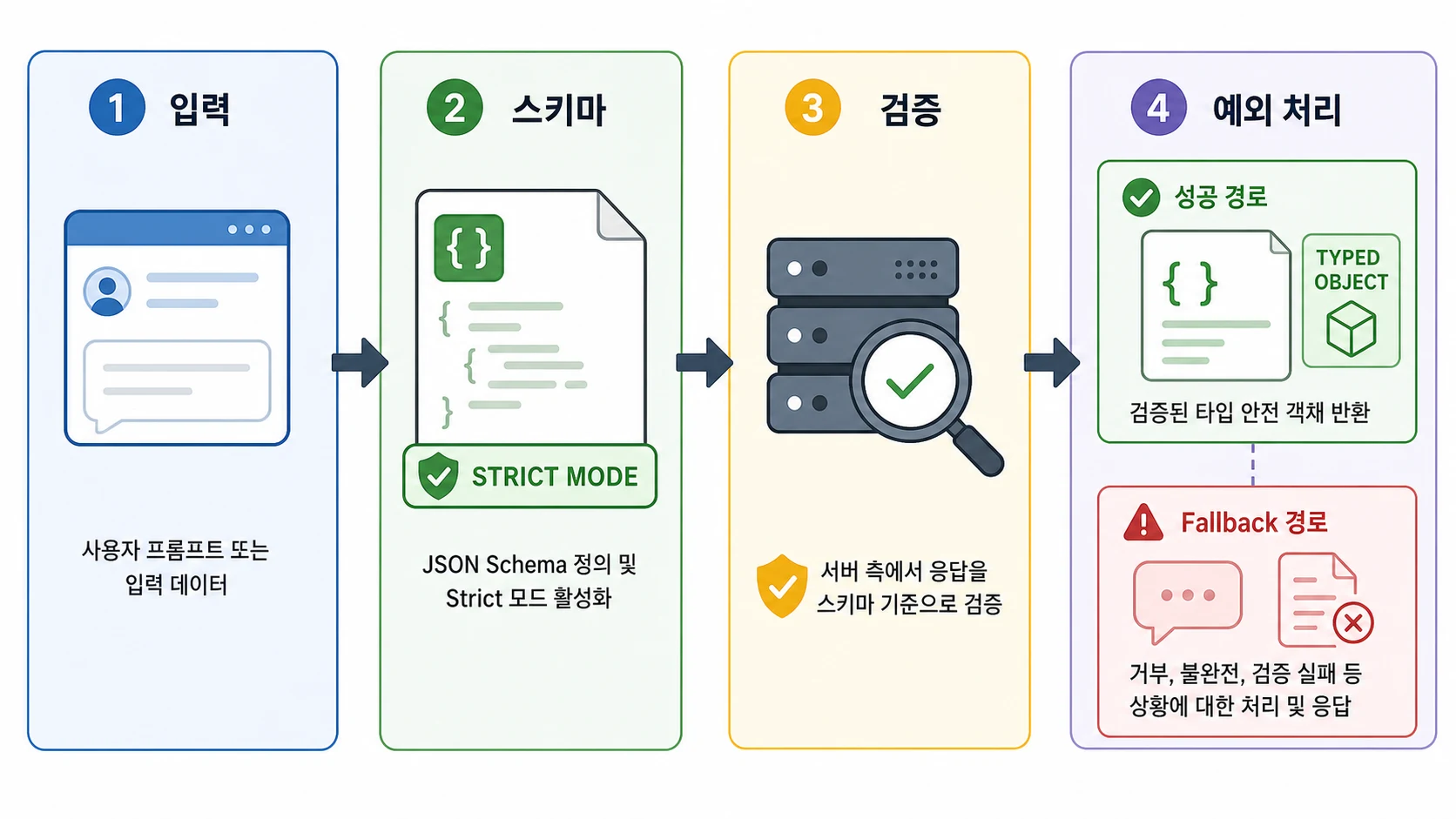
실패 처리는 어디까지 준비해야 하나요?
공식 문서 예시도 응답이 스키마에 맞지 않는 경우를 따로 다룹니다. 거절, 길이 제한, 응답 없음은 “드문 오류”로 밀어두기보다 UI와 재시도 정책에서 미리 자리를 만들어야 합니다.
| 증상 | 가능한 원인 | 처리 방법 |
|---|---|---|
| 응답이 incomplete | 토큰 제한 또는 긴 출력 | 스키마 축소, max token 조정, 사용자에게 재시도 안내 |
| refusal 응답 | 정책상 답변 거절 | 거절 메시지를 별도 상태로 저장하고 후속 작업을 멈춤 |
| 검증기에서 실패 | 스키마 누락, 타입 불일치, 추가 필드 | raw response를 그대로 쓰지 말고 validation error만 기록 |
| 값은 맞지만 사실이 틀림 | 형식 검증과 사실 검증을 혼동 | 출처 확인, 업무 규칙 검증, 사람이 볼 단계 추가 |
작게 시작하는 schema 예시
아래는 문의 분류처럼 단순한 작업에 맞는 형태입니다. 그대로 복사하기보다, 필드 이름과 enum을 실제 업무에 맞게 줄이는 쪽이 좋습니다.
{
"type": "object",
"properties": {
"category": {
"type": "string",
"enum": ["billing", "technical", "account", "other"]
},
"priority": {
"type": "string",
"enum": ["low", "normal", "high"]
},
"summary": {
"type": "string"
}
},
"required": ["category", "priority", "summary"],
"additionalProperties": false
}헷갈리기 쉬운 제한
Structured Outputs를 쓰면 파싱은 쉬워지지만, 운영 판단은 여전히 남습니다. 특히 요금, 모델 지원 범위, 도구 호출 방식은 공식 문서가 바뀔 수 있으니 배포 전 한 번 더 확인하는 게 좋습니다.
- 스키마 통과 후에도 출처 확인과 업무 규칙 검증 단계를 별도로 둡니다.
- 너무 큰 스키마는 응답 길이, 지연, 실패율을 키웁니다.
- 도구 호출 인자는 strict schema로 묶어도 실제 실행 권한과 데이터 접근은 앱 쪽에서 통제해야 합니다.
- 프레임워크를 쓰는 경우, OpenAI API의 schema 옵션과 프레임워크의 검증 방식이 어디에서 만나는지 확인해야 합니다.
출력 형식과 함께 운영 로그를 정리할 때는 AI API 키 유출 방지 체크리스트처럼 키 저장·로그 마스킹 항목도 같이 확인하면, 검증 실패 대응과 보안 점검을 한 흐름으로 묶기 쉽습니다.
바로 적용할 워크플로
실무에서는 “모델이 잘 답하겠지”보다 “깨졌을 때 어디서 멈추는지”를 먼저 정해야 합니다. 다음 순서로 티켓을 쪼개면 첫 배포 범위가 선명해집니다.
- 응답을 소비하는 코드부터 정합니다. 저장, 알림, 외부 API 호출 중 어디로 가는지 먼저 보세요.
- 그 코드가 반드시 필요로 하는 필드만 스키마로 적습니다.
- 스키마 통과 후에도 업무 규칙 검증을 한 번 더 둡니다. 예를 들어
priority가high라면 담당자 알림 조건까지 검사합니다. - 검증 실패는 재시도, 수동 검토, 사용자 재입력 중 하나로 라우팅합니다.
- 배포 뒤에는 validation error 비율과 가장 자주 깨지는 필드를 기록합니다.
자주 묻는 질문
Structured Outputs를 쓰면 검증 코드를 빼도 될까요?
모델 응답이 스키마를 따르도록 요구해도, 서버에서는 Zod, Pydantic, JSON Schema validator 같은 검증기를 한 번 더 거쳐야 합니다. 이 단계가 있어야 실패 원인을 로그로 남기고, 사용자에게 재입력이나 재시도 안내를 줄 수 있습니다.
기존 JSON mode를 바로 바꿔야 하나요?
새 기능이라면 schema strict 방식으로 먼저 설계하는 편이 낫지만, 이미 안정적으로 도는 기능은 파싱 실패율, 필드 변경 빈도, 운영 로그를 보고 순서대로 옮기면 됩니다. 한 번에 바꾸기보다 중요도가 높은 저장·알림·업무 자동화 흐름부터 점검하세요.
스키마가 커질수록 좋은가요?
필드가 많아질수록 응답 길이와 실패 처리도 커집니다. 처음에는 꼭 필요한 필드만 남기고, 설명문이나 사람이 읽는 요약은 별도 필드로 분리한 뒤 실제 실패 사례를 보며 늘리는 쪽이 안전합니다.